Master of Data Science (Global) Program
 Application closes on
28th Aug 2025
Application closes on
28th Aug 2025

 Speak with our expert
+1 512 890 1269
Speak with our expert
+1 512 890 1269




Learn more about the course
Get details on syllabus, projects, tools, and more
This program is not available in your region, please visit this webpage for details of a similar program.
Continue to check out similar courses available to you
EXPLORE COURSES Program")
Master of Data Science (Global) Program
Master Data Science for impactful career growth
Application closes 28th Aug 2025
What's new in this Master's in Data Science?
-

Advanced Modules on ChatGPT & Generative AI
Discover cutting-edge ChatGPT and Generative AI modules to revolutionize Data Science. Learn to streamline workflows, extract insights, and tackle complex business problems.
-
AI & Business Analytics Modules
Explore a curriculum that combines Data Science and AI. Gain insights into business analytics and consulting while learning to solve problems using business frameworks.
Program Outcomes
Elevate your career with advanced Data Science & AI skills
Become a Data Scientist with advanced Data Science & AI skills
-

Develop a deep understanding of the Data Science and AI landscape
-
Master essential tools like Python to solve real-world business problems
-
Master Data Science, Deep Learning, Analytics, and GenAI to drive strategic decisions
-
Secure your dream career in Data Science with our dedicated career support
Earn a master's degree from Deakin University
-
Top 1% of Universities globally (QS 2025)
-
Victorian Government Award 2020
-
World Education Services (WES) Recognized
Key program highlights
Why choose the Master of Data Science (Global) program
-
A global masters degree & PG certificates
Gain the recognition of a global masters degree and PG certificates from global universities at just 1/10th the cost of a 2 year on-campus masters
-
Practical, hands-on learning from world-class faculty
Live virtual classes, Industry sessions and competency courses delivered by experts and faculty at Deakin
-
Industry-ready curriculum
Curriculum designed in a modular structure with foundational and advanced competency track
-
Dedicated career support
Get expert guidance to prepare for job roles with mock interviews, resume building, and e-portfolio review
-
11 hands-on projects & 22+ tools
The program includes 11 hands-on projects, 1 capstone project, 60+ case studies, and 22+ tools to strengthen practical and conceptual knowledge.
-
On-campus graduation ceremony in Australia
Opportunity to attend a graduation ceremony (optional) at the Deakin University campus in Melbourne.
-
Connect with your alumni community
Join the alumni portal with over 300,000 Deakin graduates, reconnect, and meet with fellow alumni across the globe.
-
Deakin credentials and alumni benefits
Enrolled students receive Deakin email IDs and, as alumni, are eligible for a 10% discount per unit on enrolment fees for any postgraduate award course at Deakin.*
*Terms and Conditions apply





Skills you will learn
Machine Learning
SQL
Predictive Modeling
Python
Natural Language Processing (NLP)
Data Visualization using Tableau
Neural Networks & Computer Vision
Data Analysis
Deep Learning
Generative AI
Prompt Engineering
Model Deployment
Hugging face
Supervised Learning
Unsupervised Learning
Machine Learning
SQL
Predictive Modeling
Python
Natural Language Processing (NLP)
Data Visualization using Tableau
Neural Networks & Computer Vision
Data Analysis
Deep Learning
Generative AI
Prompt Engineering
Model Deployment
Hugging face
Supervised Learning
Unsupervised Learning
view more
Secure top Data Science jobs
-
11.5 million
jobs in India by 2026
-
$303 billion
market growth by 2030
-
4 out of 5
companies use Data Science
-
Up to 23 lakhs
avg annual salary
Careers in Data Science
Here are the ideal job roles in Data Science sought after by companies in India
-
Data Scientist
-
Machine Learning Engineer
-
Business Analyst
-
Data Architect / Data Warehouse Architect
-
AI Architect
-
Analytics Manager
-
Data Analyst
-
Big Data Engineer
-
Business Intelligence Analyst
Our alumni work at top companies
- Overview
- Career Transitions
- Learning Path
- Curriculum
- Projects
- Tools
- Certificate
- Faculty
- Career support
- Fees
- FAQ

This program is ideal for
The Master of Data Science (Global) program from Deakin University empowers you to align your learning with your professional aspirations
-
Young professionals & new graduates
Build a foundation in Data Science with Python, Tableau, and Machine Learning. Gain real-world experience to kickstart your Data Science career.
-
Mid-senior professionals
Boost your analytics skills with AI, Deep Learning, and Business Analytics to advance into strategic roles in the field of Data Science.
-
Non-tech professionals
Break into the world of Data Science with beginner-friendly modules and hands-on learning. Acquire the skills to transform data into actionable insights and seamlessly switch to a data-driven career.
-
Tech Leaders
Lead AI innovation with strategic insights, advanced AI & ML skills, and the ability to drive business transformation.
Learning Path
With credentials from globally recognised universities, graduates of Deakin’s Master of Data Science (Global) program are strong contenders for high-impact roles in the data science industry.
-
Earn PG certificates from world's leading institutions
Learners will join the Post Graduate Program by The University of Texas at Austin and receive the PG Certificates upon program completion.
-
Join the 12-month Deakin University program
Post completion of the PG Program from The University of Texas at Austin , candidates will continue their learning journey with the 12-month online Master of Data Science (Global) from Deakin University.
-
Earn a Master's Degree from Deakin University
Once you complete the program successfully, you will receive the Master of Data Science (Global) Degree from Deakin University.




Curriculum
Data Science Pathway
PGP-DSBA CURRICULUM The curriculum of the PGP in Data Science and Business Analytics has been updated in consultation with industry experts, academicians and program alums to ensure you learn the most cutting-edge topics.
DATA SCIENCE FOUNDATIONS
Module 1: Statistical Methods for Data Science
Descriptive Statistics
Introduction to Probability
Probability Distributions
Hypothesis Testing and Estimation
Goodness of Fit
Module 2: Business Finance
Fundamentals of Finance
Working Capital Management
Capital Budgeting
Capital Structure
Module 3: Marketing and CRM
Core Concepts of Marketing
Customer Lifetime Value
Module 4: SQL Programming
Introduction to DBMS
ER Diagram
Schema Design
Key Constraints and Basics of Normalization
Joins
Subqueries Involving Joins and Aggregations
Sorting
Independent Subqueries
Correlated Subqueries
Analytic Functions
Set Operations
Grouping and Filtering
DATA SCIENCE TECHNIQUES
Module 1: Inferential Statistics
Analysis of Variance
Regression Analysis
Dimension Reduction Techniques
Module 2: Predictive Modeling
Multiple Linear Regression (MLR) for Predictive Analytics
Logistic Regression
Linear Discriminant Analysis
Module 3: Machine Learning-1
Introduction to Supervised and Unsupervised Learning
Clustering
Decision Trees
Random Forest
Neural Networks
Module 4: Machine Learning-2
Handling Unstructured Data
Machine Learning Algorithms
Bias Variance Trade-o
Handling Unbalanced Data
Boosting
Model Validation
Module 5: Time Series Forecasting
Introduction to Time Series
Correlation
Forecasting
Autoregressive Models
Module 6: Optimization Techniques (Self-Paced)
Linear Programming
Goal Programming
Integer Programming
Mixed Integer Programming
Distribution and Network Models
DOMAIN EXPOSURE
Module 1: Demystifying ChatGPT and Applications (Self-Paced)
Overview of ChatGPT and OpenAI
Timeline of NLP and Generative AI
Frameworks for Understanding ChatGPTand Generative AI
Implications for Work, Business, and Education
Output Modalities and Limitations
Business Roles to Leverage ChatGPT
Prompt Engineering for Fine-Tuning Outputs
Practical Demonstration and Bonus Section on RLHF
Module 2: Marketing and Retail Analytics
Marketing and Retail Terminologies
Customer Analytics
KNIME
Retail Dashboard
Customer Churn
Association Rules Mining
Module 3: Web and Social Media Analytics
Web Analytics: Understanding the Metrics
Basic and Advanced Web Metrics
Google Analytics: Demo and Hands-On
Campaign Analytics
Text Mining
Module 4: Finance and Risk Analytics
Why Credit Risk: Using a Market Case Study
Comparison of Credit Risk Models
Overview of Probability of Default (PD) Modeling
PD Models, Types of Models, Steps to Make a Good Model
Market Risk
Value at Risk: Using Stock Case Study
Module 5: Supply Chain and Logistics Analytics
Introduction to Supply Chain
RNNs and its Mechanisms
Designing an Optimal Strategy Using Case Study
Inventory Control and Management
Inventory Classification
Inventory Modeling
Costs Involved in Inventory
Economic Order Quantity
Forecasting
Advanced Forecasting Methods
Examples and Case Studies
VISUALIZATION AND INSIGHTS
Module 1: Data Visualization Using Tableau
Introduction to Data Visualization
Introduction to Tableau
Basic Charts and Dashboard
Descriptive Statistics, Dimensions and Measures
Visual Analytics: Storytelling through Data
Dashboard Design and Principles
Advanced Design Components/ Principles: Enhancing the Power of Dashboards
Special Chart Types
Case Study: Hands-On Using Tableau
Integrate Tableau with Google Sheets
AIML Pathway
PGP-AIML CURRICULUM
The curriculum of the PGP in Artificial Intelligence & Machine Learning has been updated in consultation with industry experts, academicians & program alums to ensure you learn the most cutting-edge topics:
Python and GenAI Prep Work
Python Bootcamp for Non-programmers
Python Prep Work
Generative AI Prep Work
Course 1: Introduction to Python
Python Programming Python for Data Science Exploratory Data Analysis (EDA) Analyzing Text Data
Course 2: Machine Learning
Linear Regression
Decision Trees
K-Means Clustering
Course 3: Advanced Machine Learning
Bagging
Boosting
Model Tuning
Course 4: Introduction to Neural Networks
Introduction to Neural Networks
Optimising Neural Networks
Course 5: Natural Language Processing with Generative AI
Word Embeddings
Attention Mechanism and Transformers
Large Language Models and Prompt Engineering
Retrieval Augmented Generation
Course 6: Introduction to Computer Vision
Image Processing
Convolutional Neural Networks
Course 7: Model Deployment
Introduction to Model Deployment
Containerisation
Course 8: Introduction to SQL
Querying Data With SQL Advanced Querying Enhancing Query Proficiency
Course 9:Applied Statistics
Inferential Statistics Foundations Estimation and Hypothesis Testing Common Statistical Tests
Course 10: Advanced Machine Learning and MLOPS
Model Interpretability Introduction to MLOps and DevOps Building ML Pipelines
Course 11:Advanced Generative AI for Natural Language Processing
AI Assistant Development Fine-tuning LLMS
Course 12:Capstone
Additional Modules (Learn at your own Pace)
Course 1: Introduction to Data Science and AI Course 2: Multimodal Generative AI
Course 3: Recommendation Systems
Course 4: Object Detection and Segmentation
Course 5: Reinforcement Learning
Course 6: Time Series Forecasting
Second Year: Masters of Data Science (Global)
TRIMESTER 1
ENGINEERING AI SOLUTIONS
LEARNING OUTCOMES OF THIS UNIT:
Explain the process and key characteristics of developing an AI solution, and the contrast with traditional software development, to inform a range of stakeholders
Design, develop, deploy, and maintain AI solutions utilising modern tools, frameworks, and libraries
Apply engineering principles and scientific method with appropriate rigour in conducting experiments as part of the AI solution development process
Manage expectations and advise stakeholders on the process of operationalising AI solutions from concept inception to deployment and ongoing product maintenance and evolution
MATHEMATICS FOR ARTIFICIAL INTELLIGENCE
LEARNING OUTCOMES OF THIS UNIT:
Explain the role and application of mathematical concepts accociated with artificial intelligence
Identify and summarise mathematical concepts and technique covered in the unit needed to solve mathematical problems from artificial intelligence applications
Verify and critically evaluate results obtained and communicate results to a range of audiences
Read and interpret mathematical notation and communicate the problem-solving approach used
TRIMESTER 2
MACHINE LEARNING
LEARNING OUTCOMES OF THIS UNIT:
Use Python for writing appropriate codes to solve a given problem
Apply suitable clustering/dimensionality reduction techniques to perform unsupervised learning on unlabelled data in a real-world scenario
Apply linear and logistic regression/classification and use model appraisal techniques to evaluate develop models
Use the concept of KNN (k-nearest neighbourhood) and SVM (support vector machine) to analyse and develop classification models for solving real-world problems
Apply decision tree and random forest models to demonstrate multi-class classification models
Implement model selection and compute relevant evaluation measure for a given problem
MODERN DATA SCIENCE
LEARNING OUTCOMES OF THIS UNIT:
Develop knowledge of and discuss new and emerging fields in data science
Describe advanced constituents and underlying theoretical foundation of data science
Evaluate modern data analytics and its implication in real-world applications
Use appropriate platform to collect and process relatively large datasets
Collect, model and conduct inferential as well predictive tasks from data
TRIMESTER 3
REAL-WORLD ANALYTICS
LEARNING OUTCOMES OF THIS UNIT:
Apply knowledge of multivariate functions data transformations and
data distributions to summarise data sets
Analyse datasets by interpreting summary statistics, model and function parameters
Apply game theory, and linear programming skills and models, to make optimal decisions
Develop software codes to solve computational problems for real world analytics
Demonstrate professional ethics and responsibility for working with real world data
DATA WRANGLING
LEARNING OUTCOMES OF THIS UNIT:
Undertake data wrangling tasks by using appropriate programming and scripting languages to extract, clean, consolidate, and store data of different data types from a range of data sources
Research data discovery and extraction methods and tools and apply resulting learning to handle extracting data based on project needs
Design, implement, and explain the data model needed to achieve project goals, and the
processes that can be used to convert data from data sources to both technical and
non-technical audiences
Use both statistical and machine learning techniques to perform exploratory analysis on
data extracted, and communicate results to technical and non-technical audiences
Apply and reflect on techniques for maintaining data privacy and exercising ethics in data handling
Work on 11 hands-on projects
Dive into Data Science, AI and Machine Learning projects to sharpen skills and build a unique portfolio
-
11
hands-on projects
-
60+
case studies
-
22+
domains
FOOD AND BEVERAGES
Customer Demand Insights for FoodHub Restaurants
Description
Conduct exploratory data analysis to assess demand for restaurants and cuisines, providing insights to enhance customer experience and boost business for a food aggregator.
Skills you will learn
- Python
- Numpy
- Pandas
- Seaborn
- Univariate Analysis
- Bivariate Analysis
- Exploratory Data Analysis
BFSI
Loan Purchase Prediction from Marketing Campaign Data
Description
Analyze historical marketing campaign data of a bank and build a machine learning model that will help to identify the customers of a bank who are exposed to a marketing campaign and have a higher probability of purchasing a loan.
Skills you will learn
- Exploratory Data Analysis
- Decision Trees
- Pruning
- Scikit-Learn
- Pandas
- Seaborn
Immigration
Predictive Model for Visa Status Determination
Description
Analyze visa applicant data to build a predictive model that identifies key factors influencing visa status and recommends whether an applicant should be approved or denied.
Skills you will learn
- Exploratory Data Analysis
- Data Preprocessing
- Bagging
- Random Forest
- Boosting
- AdaBoost
- Gradient Boosting
- XGBoost
- GridSearchCV
Energy
Optimizing Wind Turbine Maintenance with Neural Network Models
Description
Analyze data from a wind energy provider to build neural network models that predict equipment failures, enabling timely repairs and reducing maintenance costs
Skills you will learn
- Exploratory Data Analysis
- Data Preprocessing
- Tensorflow
- Keras
- Artificial Neural Networks
- Regularization
Master in-demand Data Science and AI tools
Gain hands-on experience with 22+ top Data Science & AI tools to optimize models and build innovative solutions
-
Python
-
SQL
-
NumPy
-
Pandas
-
Seaborn
-
scikit-learn
-
Keras
-
Tensorflow
Earn a Degree and PG certificates from world's leading institutions
-
Earn a globally recognized Master of Data Science degree from Deakin University.
-
Get PG Certificates in “AI and Machine Learning” or “Data Science and Business Analytics” from McCombs School of Business at The University of Texas at Austin .
-
Stand out globally with an AQF level 9 degree from Deakin University, officially recognised through Australian Higher Education Graduation Statement (AHEGS).







* Image for illustration only. Certificate subject to change.
Meet your faculty
Meet our expert faculty with in-depth Data Science & AI knowledge and a passion to help you succeed
-
Dr. Sutharshan Rajasegarar
Senior Lecturer in Computer Science Course Director Master of Data Science
-
Dr. ye Zhu
Senior Lecturer, Computer Science
-
Dr. Bahareh Nakisa
Senior Lecturer, Applied Artificial Intelligence
-
Dr. Asef Nazari
Senior Lecturer, Applied Artificial Intelligence
-
Gang Li
Professor, School of Info Technology
-
Dr. Marek Gagolewski
Senior Lecturer, Applied Artificial Intelligence
-
Maia Angelova Turkedjieva
Professor, Real-World Analytics







-
Dr. Kumar Muthuraman
Professor, McCombs School of Business, the University of Texas at Austin
Faculty Director, Center for Analytics and Transformative Technologies
21+ years' experience in AI, ML, Deep Learning, and NLP.
Know More
-
Dr. Abhinanda Sarkar
Senior Faculty & Director Academics, Great Learning
30+ years of experience in data science, ML, and analytics.
Ph.D. from Stanford, taught at MIT, ISI, and IIM Bangalore.
Know More
-
Mr. R Vivekanand
Co-Founder and Director
Expert in data visualization and marketing econometrics with 10+ years
Qualified Tableau trainer passionate about teaching business analytics
Know More
-
Prof. Raghavshyam Ramamurthy
Industry Expert in Visualization
-
Dr. Daniel A Mitchell
Clinical Assistant Professor, McCombs School of Business, The University of Texas at Austin
Research Director, Center for Analytics and Transformative Technologies
15+ years of experience in financial engineering and quantitative finance.
Know More
-
Dr. Pavankumar Gurazada
Senior Faculty, Academics, Great Learning
15+ years of experience in marketing, digital marketing, and machine learning.
Ph.D. from IIM Lucknow; MBA from IIM Bangalore; IIT Bombay graduate.
Know More








Get industry ready with dedicated career support*
*Note: Provided by Great Learning
-
Resume Building Sessions
Build your resume to highlight your skill-set along with your previous academic and professional experience.
-
Access to curated jobs
Access a list of jobs relevant to your experience and domain.
-
Interview preparation
Learn to crack technical interviews with our interview preparation sessions.
-
Career Guidance
Get access to career mentoring from industry experts. Benefit from their guidance on how to build a rewarding career.




Course fees
The course fee is 8,500 USD
Invest in your career
-
Develop a deep understanding of the Data Science landscape
-
Master essential tools like Python to solve real-world business problems
-
Master Data Science, Deep Learning, Analytics, and GenAI to drive strategic decisions
-
Secure your dream career in Data Science with our dedicated career support
Easy payment plans
Avail our EMI options & get financial assistance
Third Party Credit Facilitators
Check out different payment options with third party credit facility providers
*Subject to third party credit facility provider approval based on applicable regions & eligibility

Admission Process
Admissions close once the required number of participants enroll. Apply early to secure your spot
-
1. Apply
Fill out an online application form
-
2. Get Reviewed
Go through a screening call with the Admission Director’s office.
-
3. Join the program
Your profile will be shared with the Program Director for final selection



Course Eligibility
- Applicant must meet Deakin’s minimum English Language requirement.
- Candidates should have a bachelors degree (minimum 3-year degree program) in a related discipline OR a bachelors degree in any discipline with at least 2 years of work experience
Batch start date
-
Online · To be announced
Admissions Open
Frequently asked questions
What is unique about the Deakin University Master of Data Science (Global) program?
The Master of Data Science (Global) from Deakin University is a 12+12-month online data science degree. This program is split into two parts: foundational and advanced stages. This structure ensures learners gain both practical and in-depth mastery of data science concepts and tools. Key features that set the program apart include:
Expert-Led Learning: Live online lectures delivered by Deakin’s esteemed faculty, complemented by sessions from experienced industry professionals.
Hands-on Experience: Weekly mentorship and real-world projects that reinforce practical skills and application.
Career Advancement Support: Provides robust career enhancement support, including workshops, personalized career guidance, and exclusive access to the GL Excelerate jobs portal.
Dedicated Program Assistance: Ongoing academic and career support through Great Learning enhances the overall experience and outcomes for students.
This program is a top choice for those who want to work in AI, machine learning, and data science. It offers academic excellence, industry connections, and support for building a career.
What is the Master of Data Science (Global) Program from Deakin University?
The Master of Data Science (Global) is a 12+12-month online program designed with a modular structure by unbundling the curriculum into foundational and advanced competency tracks, which enable learners to master advanced Data Science skill sets effectively.
The program is designed to equip students with the industry-relevant skills and knowledge required to pursue their careers in the cutting-edge fields of Data Science, Business Analytics.
The online mode of learning will furthermore let the students continue working while upgrading their skills and saving up on accommodation costs. With globally recognised credentials from leading universities (UT Austin & Deakin University), graduates of the Master of Data Science (Global) from Deakin University become prime candidates for accelerated career progression in the Data Science field.
Do I need to give the GRE or GMAT test to qualify for this program?
No, you are not required to attempt GRE or GMAT tests. The candidates who meet the eligibility criteria are eligible to pursue this program.
What are the payment options available to pay my program fee?
The program fee can be paid by candidates through net banking, credit cards, or debit cards.
Is there a refund policy for this program?
There are no refund policies for this program. However, a few exceptional cases are considered at our discretion.
What is the deadline to enrol in this Master of Data Science (Global) Program?
Once the required number of participants has signed up for the upcoming batch, our admissions are closed. The first-come, first-serve policy applies to the few seats available for this program. To guarantee your seats, apply early.
 Application Closes
28th Aug 2025
Application Closes
28th Aug 2025

Similar free Data Science courses for you
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Applying Analytics to Business Problems
-

 Beginner
Beginner
 1.5 Hrs
1.5 Hrs
Data Analytics using Excel
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Apriori Algorithm
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
Applications of Data Science & Machine Learning
-

 Beginner
Beginner
 3.0 Hrs
3.0 Hrs
Python for Machine Learning and Data Science
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
LDA in Entertainment Industry
-

 Intermediate
Intermediate
 0.5 Hrs
0.5 Hrs
Predict Footballer Transfer Market Value using Data Science
-

 Beginner
Beginner
 3.0 Hrs
3.0 Hrs
Marketing and Retail Analytics
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Forecasting Hospital Blood Requirements
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
k-fold Cross Validation










Explore latest trends & topics
-
20+ Excel Formulas List with Examples
2025-05-14 13:44:03 UTC
-
Top 60 Statistics Interview Questions 2025
2025-05-14 13:41:56 UTC
-
Top 46 MATLAB Interview Questions and Answers in 2025
2025-05-14 13:39:49 UTC
-
Data Science vs Machine Learning and Artificial Intelligence: The Difference Explained
2025-05-14 13:09:23 UTC
-
Top 9 Job Roles in the World of Data Science for 2025
2025-05-14 13:07:55 UTC
-
100+ Data Science Interview Questions in 2025
2025-05-14 13:05:48 UTC
-
Top Data Scientist Skills You Must Have In 2025
2025-05-14 13:02:49 UTC
-
Jobs in Data Science and Business Analytics
2024-11-12 10:23:26 UTC
-
What is Data Science? - The Complete Guide
2024-01-24 07:28:57 UTC
-
How to Make the Career Transition From Data Analyst to Data Scientist?
2022-09-23 09:24:30 UTC










Batch Profile
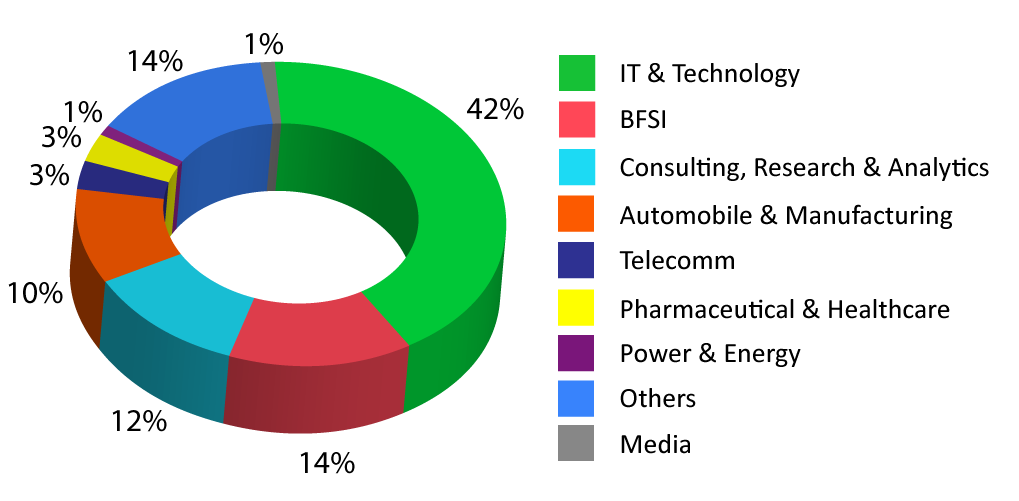
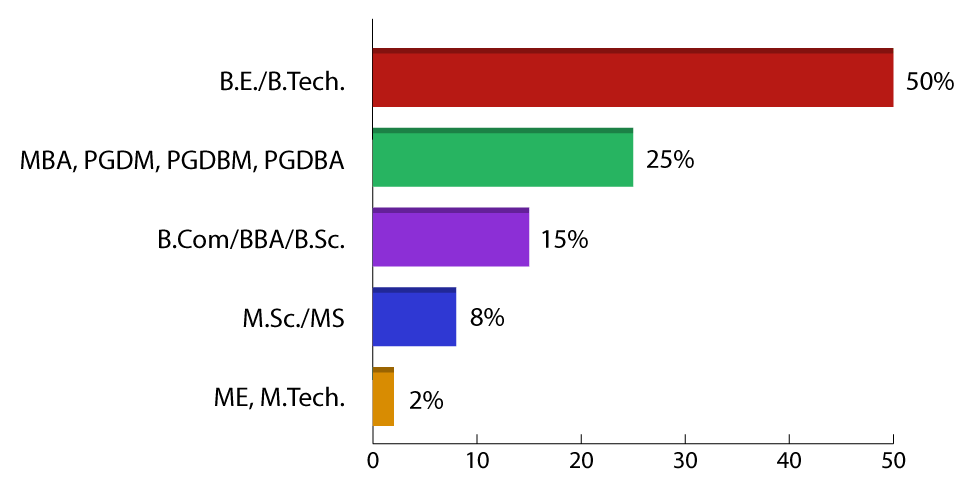
The PGP-Data Science class consists of working professionals from excellent organizations and backgrounds maintaining an impressive diversity across work experience, roles and industries.
Batch Industry Diversity
Batch Work Experience Distribution
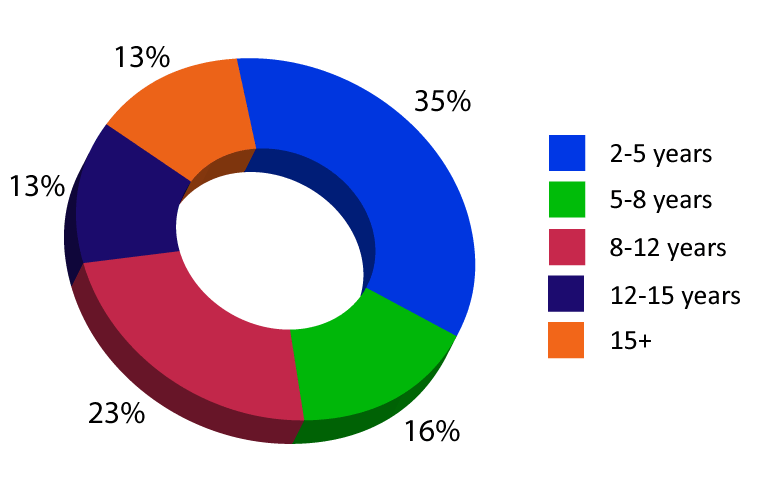
Batch Education Diversity
The PGP-Data Science learners come from some of the leading organizations.

Master of Data Science (Global) Program - Deakin University, Australia
Deakin University in Australia offers its students a top-notch education, outstanding employment opportunities, and a superb university experience. Deakin is ranked among the top 1% of universities globally (Shanghai Rankings) and is one of the top 50 young universities worldwide.
The curriculum designed by Deakin University strongly emphasizes practical and project-based learning, which is shaped by industry demands to guarantee that its degrees are applicable today and in the future.
The University provides a vibrant atmosphere for teaching, learning, and research. To ensure that its students are trained and prepared for the occupations of tomorrow, Deakin has invested in the newest technology, cutting-edge instructional resources, and facilities. All students will obtain access to their online learning environment, whether they are enrolled on campus or studying only online.
Why pursue the Data Scientist Masters Program at Deakin University, Australia?
The Master's Degree from Deakin University provides a flexible learning schedule for contemporary professionals to achieve their upskilling requirements. In addition, you can:
- Get a globally recognized Master's Degree from Deakin University and a Post Graduate Certificate from UT Austin.
- Learn Data Science and Business Analytics from reputed faculty through live, interactive online sessions.
- Develop your skills with a curriculum created by eminent academicians and industry professionals.
- Gain practical knowledge and skills by engaging in project-based learning.
- Become market-ready with mentorship sessions from industry experts.
- Learn alongside a diverse group of peers and professionals for a rich learning experience.
- Secure a Global Data Science Master’s Degree at 1/10th the cost of a 2-year traditional Master’s program.
Benefits of Deakin University Master’s Course of Data Science (Global)
Several benefits are offered throughout this online Data Science degree program, which include:
PROGRAM STRUCTURE
Deakin University's Master of Data Science (Global) Program has a modular structure that separates the curriculum into basic and advanced competency tracks, allowing students to master advanced Data Science skills alongside Business Analytics.
INDUSTRY EXPOSURE
Candidates gain exposure and insights through industry workshops and competency classes led by world-class industry experts and faculty.
WORLD-CLASS FACULTY
The faculty's extensive experience in both academia and industry enables them to effectively teach the most current, in-demand skills.
CAREER ENHANCEMENT SUPPORT
The program offers career development support through workshops and mentorship sessions to help applicants identify their strengths and career paths.
The Advantage of Great Learning in this Deakin University’s Master of Data Science Course
Great Learning is the world’s leading ed-tech platform providing industry-relevant programs for professional learning and higher education. This course gives you access to a comprehensive network of industry experts and committed career support.
E-PORTFOLIO
An e-portfolio illustrates the skills you have acquired and the knowledge you have gained, which can be shared on social media to showcase your expertise to potential employers.
CAREER SUPPORT
The course provides students with career support, empowering them to advance their professions.
RESUME BUILDING AND INTERVIEW PREPARATION
The program assists in creating a resume that highlights your abilities and work experience, while interview preparation workshops help you ace your interviews.
CAREER MENTORSHIP
Access personalized career mentorship sessions from highly skilled industry experts who guide you towards developing a lucrative career.
Eligibility for Master of Data Science (Global) Program
The following are the requirements for program eligibility:
- Interested candidates must hold a bachelor's degree (minimum 3-year program) in a related field or a bachelor's degree in any discipline with at least 2 years of professional work experience.
- Candidates must meet Deakin University’s minimal English language requirement.
Hey there! Welcome back.


Forgot your password? No problem.

You are already registered. Please login instead.
Login
Forgot Password?
Enter your registered email and we'll send you a link to change your password.